Apify를 ClickHouse에 연결
Apify는 웹 스크래핑 및 자동화 플랫폼입니다. Actors라고 하는 서버리스 클라우드 프로그램을 구축하고 실행하며 확장할 수 있습니다. Actors는 웹사이트를 스크래핑하거나 웹을 크롤링하고, 데이터를 처리하거나 워크플로를 자동화합니다. 각 Actor 실행은 Datasets에 저장되는 구조화된 출력(JSON 객체의 모음)을 생성합니다.
스크래핑하거나 처리한 데이터를 분석, 모니터링 또는 데이터 보강 파이프라인에 활용할 수 있도록 ClickHouse에 적재하십시오.
핵심 개념
| Apify 개념 | 설명 |
|---|---|
| Actor | Apify 플랫폼에서 실행되는 서버리스 클라우드 프로그램입니다. Apify Store에서는 바로 사용할 수 있는 수천 개의 Actor를 제공합니다. |
| Dataset | Actor 실행 결과로 생성되는 출력입니다. Apify API를 통해 JSON, CSV, XML 또는 기타 형식으로 가져올 수 있는, 테이블과 유사한 JSON 객체 모음입니다. |
| Webhook | Actor 실행이 성공하거나 실패했을 때 또는 기타 수명 주기 이벤트가 발생했을 때 트리거되는 이벤트 기반 HTTP 호출입니다. 웹훅을 사용해 Apify와 ClickHouse 간 파이프라인을 자동화하십시오. |
설정 가이드
ClickHouse 연결 정보 수집하기
HTTP(S)로 ClickHouse에 연결하려면 다음 정보가 필요합니다:
| Parameter(s) | Description |
|---|---|
HOST and PORT | 일반적으로 TLS를 사용할 때는 포트가 8443이고, TLS를 사용하지 않을 때는 8123입니다. |
DATABASE NAME | 기본적으로 default라는 데이터베이스가 있으며, 연결하려는 데이터베이스의 이름을 사용합니다. |
USERNAME and PASSWORD | 기본값으로 사용자 이름은 default입니다. 사용하려는 용도에 적합한 사용자 이름을 사용합니다. |
ClickHouse Cloud 서비스에 대한 세부 정보는 ClickHouse Cloud 콘솔에서 확인할 수 있습니다. 서비스를 선택한 다음 Connect를 클릭하십시오:
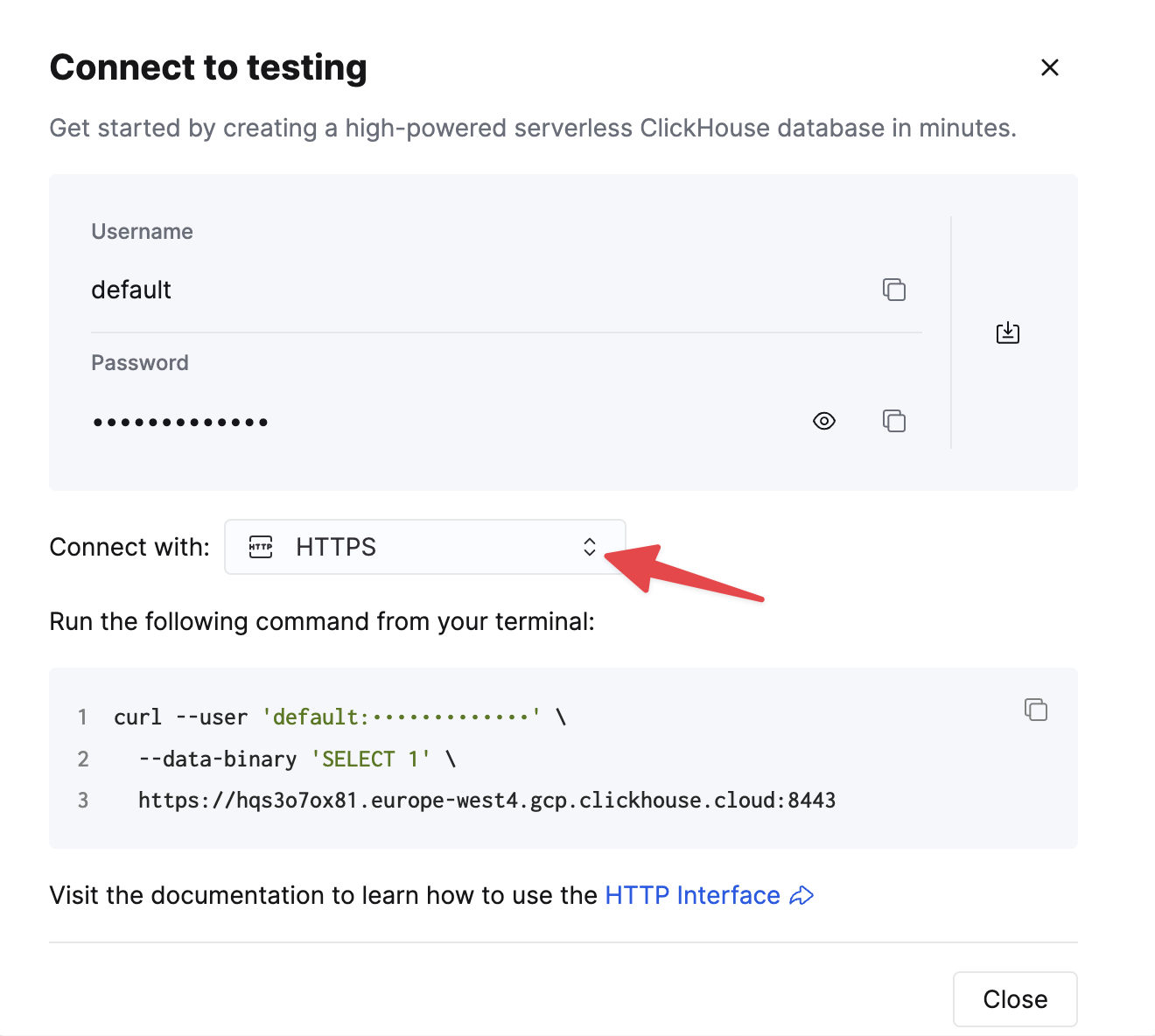
HTTPS를 선택하십시오. 연결 정보는 예제 curl 명령에 표시됩니다.
자가 관리형 ClickHouse를 사용하는 경우, 연결 정보는 ClickHouse 관리자가 설정합니다.
Apify 사전 요구 사항
다음 항목도 필요합니다:
- Apify 계정 (무료 티어 사용 가능)
- Apify API 토큰 - Apify Console의 Settings > Integrations에서 확인할 수 있습니다.
- 로컬에 설치된 Node.js 18+ (JavaScript 예시용)
의존성 설치
Apify JavaScript client와 ClickHouse JavaScript client를 설치하십시오:
Apify는 Python client도 제공합니다. Python을 선호하는 경우 pip로 apify-client를 설치하고, ClickHouse에는 clickhouse-connect를 사용하십시오.
Apify 데이터셋 가져와 ClickHouse에 로드하기
다음 스크립트는 Apify Actor 실행 결과를 가져와 ClickHouse에 삽입합니다:
대규모 데이터셋의 경우 List dataset items 엔드포인트의 limit 및 offset 매개변수를 사용해 결과를 페이지 단위로 가져오십시오. 비어 있지 않고 중복이 제거된 항목만 가져오려면 clean=true도 전달할 수 있습니다.
웹훅으로 자동화하기
스크립트를 수동으로 실행하는 대신, Actor가 완료될 때마다 데이터가 ClickHouse에 로드되도록 파이프라인을 자동화하십시오:
- Apify Console에서 해당 Actor로 이동한 다음 Integrations 탭을 여십시오.
- 다음과 같이 새 웹훅을 추가하십시오:
- Event type:
ACTOR.RUN.SUCCEEDED - Action: 로더 엔드포인트로 HTTP POST를 보내거나, ClickHouse 삽입을 처리하는 다른 Actor를 트리거합니다.
- Event type:
- 웹훅 payload에는
defaultDatasetId가 포함되며, 이를 사용해 실행 결과를 가져올 수 있습니다.
payload 세부 정보와 설정 옵션은 Apify 웹훅 문서를 참조하십시오.
다른 방법으로는 Apify Schedules를 사용해 cron과 유사한 일정으로 Actor를 실행하고, 로드 단계에는 웹훅을 함께 사용하는 방식이 있습니다.
모범 사례
Apify에서 데이터 가져오기
직접 HTTP 호출을 사용하는 대신 Apify 클라이언트 라이브러리(JavaScript용 apify-client 또는 Python용)를 사용하세요. 이 라이브러리는 페이지네이션, 재시도, 인증을 자동으로 처리합니다. 대규모 데이터셋의 경우 List dataset items 엔드포인트의 limit 및 offset 매개변수를 사용해 결과를 페이지별로 나누어 가져오세요.
ClickHouse에 로드하기
ClickHouse에 삽입할 때는 JSONEachRow 형식을 사용하십시오. 별도의 변환 없이 Apify의 JSON 출력에 바로 매핑됩니다.
ClickHouse 테이블의 schema를 Actor의 출력 필드에 맞추십시오. Actor의 출력 schema는 Apify Store 페이지 또는 실행 후 Dataset 탭에서 확인할 수 있습니다.
성능
JavaScript 클라이언트에서 높은 처리량으로 삽입하려면 성능 최적화를 위한 팁을 따르십시오. 한 번에 한 행씩 삽입하지 말고 여러 행을 묶어 더 큰 단위로 삽입하며, 클라이언트 측에서 배치 처리하기 어려운 경우 비동기 삽입을 고려하십시오.
보안
이 페이지의 예시는 설명을 단순화하기 위해 default 사용자와 데이터베이스를 사용합니다. 프로덕션에서는 대상 테이블에 삽입하는 데 필요한 최소 권한만 부여된 전용 사용자를 생성하고, 자격 증명은 안전하게 저장하십시오(예를 들어 소스 코드에 커밋하지 말고 환경 변수나 시크릿 관리 도구를 사용하십시오). 자세한 지침은 Cloud 접근 관리를 참조하십시오.
